





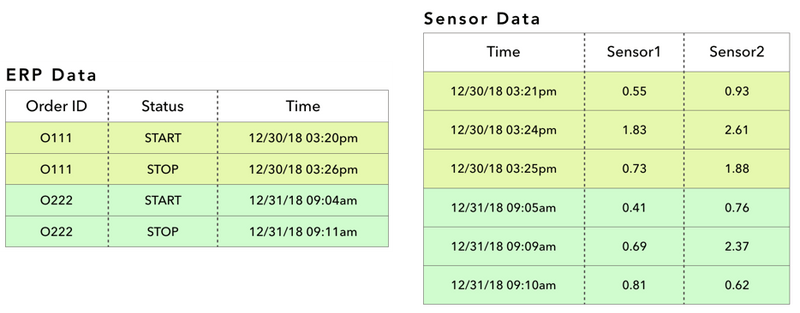
Here’s a scenario (that happens to be typical in the manufacturing world) – Dataset A (ERP data) contains a date range, and Dataset B (Sensor Data) contains rows that fall within the date range of dataset A.
Example:

The Objective
Our goal is to combine the two datasets with “Time” as the common column. We need to place the Order ID next to the Sensor values so it looks like this:

Why this is not a trivial task
At the surface, this may look like a simple JOIN (in SQL) or VLOOKUP (in Excel) exercise, but it’s not. Because the “Time” columns in both tables describe a range of time values but not exact times. This operation involves a complex, multi-step SQL operation.If you’re trying to do this with code, you need to –
- perform an Outer JOIN with the two datasets
- Then deal with missing or null values. (which you can solve through another non-trivial piece of code.)
A simple, code-free and automated solution using Mammoth
Firstly, for those who don’t know about Mammoth Analytics, it is a lightweight, code-free data management platform. It provides powerful tools for the entire data journey, including data retrieval, consolidation, storage, cleanup, reshaping, analysis, insights, alerts and more.
Okay, let’s get started
The following steps describe how we can perform this task, easily, and in a couple of minutes.
First, you need to bring your data into Mammoth. We offer a lot of easy ways to do that.
For our example, I just uploaded the two CSV files from my computer into Mammoth.

Now, our goal is to combine two separate datasets into one and then perform some transformations on the Combined Data.

Step 1: Send the ERP data into another Dataset called “Combined Data”
To do this, open up any of the datasets, go to “Data Preparation” and use the “Merge & Branch out > Branch out to dataset” option.

Now send this data to a new Dataset called “Combined Data”

If you’ve selected “Keep this task in the data pipeline”, you’ll now see a step in the pipeline indicating your action.

Step 2: Send the Sensor data into the same “Combined Data” Dataset
Open up the Sensor Dataset and perform similar steps as Step 1, only this time it needs to be sent to the existing “Combined Data” dataset.
In your Data Library, you’ll see a new dataset called “Combined Data”.

When you open that file, you will see the following:

Step 3: Fill the missing or null values in the “Combined Data” Dataset
First, let’s sort the data in ascending order by Time.

Which gives you this:

Now, to fill the missing Order ID values, we just need to use the Fill Missing Values function.

Select the Order ID column in “fill empty cells in“ drop-down and to fill the values from the cells above the empty cell, select “above“ in “with values from“ drop-down. Its worth noticing that the grouping is not applicable here, so we will fill the missing values without adding a grouping rule.

Which gives you this final result:

And we’re done
We’ve achieved a code-free solution to combining two time-series datasets in a couple of minutes.
An extra bonus — automation is built-in. New data coming into any of the original datasets automatically sends it to the “Combined Data” Dataset
Once you’re done with this task, you can explore other ways of getting your data in the right shape using the Mammoth platform. If you want to try this same exercise yourself, download the two files below and give it a spin in Mammoth using the steps described above.
If you have any questions or comments regarding this, leave a message below or just reach us at hello@mammoth.io.


